Historique
En 1998, à l'occasion de ma thèse (report.ps.gz), pour montrer l'avantage de XML, j'ai écrit un programme pour faire du regroupement automatique de documents AML (Astronomical Markup Language). Il utilisait à la fois les liens sémantiques et les mots-clés associés aux documents, avec un algorithme de partitionnement bruité, et affichait le résultat sur une carte avec des couleurs correspondantes à la densité des documents et des titres appropriés pour chaque zone de la carte. Les documents pouvaient être obtenus automatiquement de diverses bases de données, en partant d'un document initial et en utilisant les liens AML pour obtenir les documents liés. C'était un succès, mais comme de nombreux logiciels séduisants créés à l'occasion de thèses, il a disparu du web car il ne pouvait plus être maintenu.
De retour à 2004, j'avais besoin d'un programme pour classifier automatiquement d'autres documents, et je n'ai pas trouvé de logiciel libre et gratuit pour cette simple tâche. J'ai donc décidé de ressuciter le projet, et j'ai trouvé une façon de spécifier la liste des documents, mots-clés et liens dans un document XML externe aux documents. De cette façon, le programme peut être utilisé pour n'importe quelle collection de documents, même des documents qui ne sont pas XML.
Utilisation du programme
Voilà un exemple de liste de documents, avec des mots-clés et des liens. La DTD est incluse dans le package.
<DOCLIST>
<DOCUMENT id="108">
<URL>section2_1_2_7_APPRENDRE.html</URL>
<TITLE>Vitesse orbitale</TITLE>
<KEYWORDS>
<KEYWORD>KEPLER</KEYWORD>
<KEYWORD>MASSE</KEYWORD>
<KEYWORD>MOUVEMENT</KEYWORD>
<KEYWORD>TRAJECTOIRE</KEYWORD>
<KEYWORD>VITESSE</KEYWORD>
</KEYWORDS>
<LINKS>
<LINK toid="110"/>
</LINKS>
</DOCUMENT>
</DOCLIST>
Une fois que la liste des documents est prête, le programme de clustering peut être lancé (il suffit de double-cliquer sur Clustering.jar).
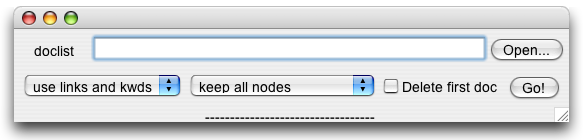
L'algorithme de clustering commence par placer les documents au hasard sur la grille, puis les déplace de façon à réduire le "coût" progressivement. Après un moment, il s'arrête et le résultat est enregistré dans un fichier grid.xml.
Ce fichier XML contenant la grille peut ensuite être affiché avec l'appliquette DispGrid, à l'aide d'un fichier HTML contenant ce code:
<applet code="dispgrid.DispGrid" archive="DispGrid.jar" width="100" height="100">
<param name="url" value="http://server/grid.xml">
</applet>
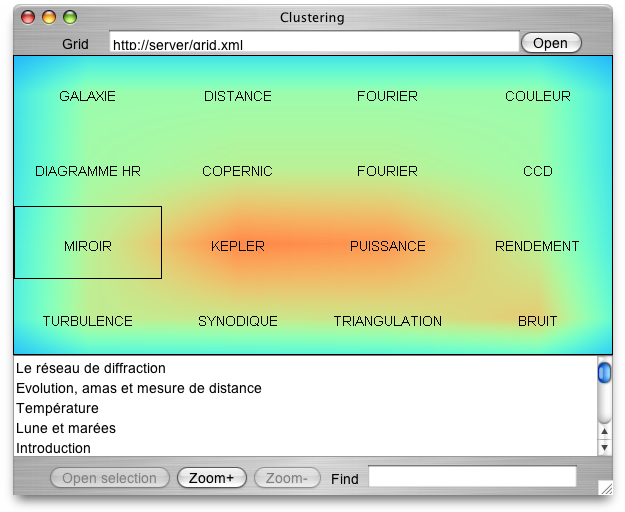
Problèmes
Attention, certains navigateurs bloquent l'affichage d'une nouvelle fenêtre par les applets :
Internet Explorer avec Windows XP SP2 (ça marchait avant) ou le bloqueur de pop-ups de Google bar, Firefox 1.5 (ça marchait avant).
Cela empêche l'applet d'afficher les pages web que l'on sélectionne.